+91-8087166655 (24x7) [email protected]
+91-8087166655 (24x7) [email protected]

OPTIMISTIK INFOSYSTEMS | Monday, August 12, 2019 | Category: Kubernetes
Kubernetes is a software that allows deployment, management and scaling of applications. The applications will be packed in containers and kubernetes groups them into units. It allows us to span our application over thousands of servers while looking like one single unit.
With more than a decade of experience of running production workloads at Google with Google’s internal container cluster managers Borg and Omega, Kubernetes started in 2014. It made the adaption of emerging software architectural patterns such as microservices, serverless functions, service mesh, and event-driven applications much easier paving the path towards the entire cloud-native ecosystem. Most importantly, its cloud agnostic design made containerized applications to run on any platform without any changes to the application code. Today, the use of Kubernetes for large enterprise deployments as well as any small to medium-scale enterprises can save a considerable amount of infrastructure and maintenance costs in the long run.
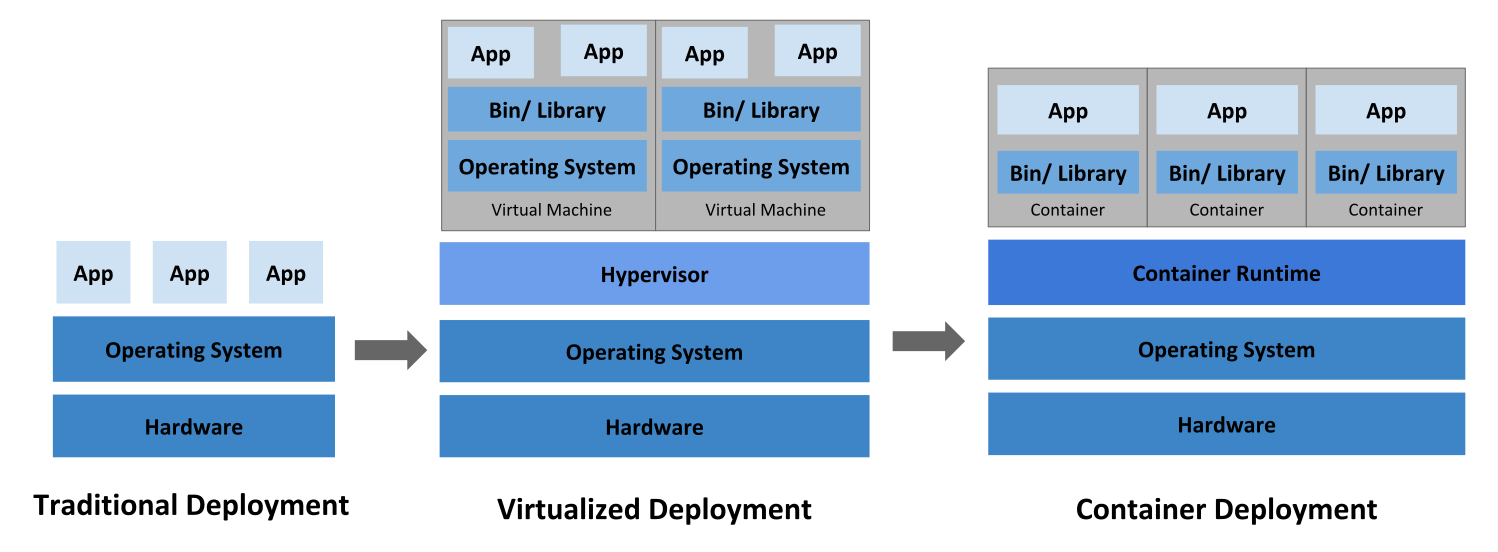
Early on, organizations ran applications on physical servers. It was impossible to define resource boundaries for applications in a physical server creating resource allocation issues. Say if multiple applications run on a physical server, there can be instances where one application would take up most of the resources resulting in the underperformance of the other applications. Running each application on a different physical server can be a solution for this. But to maintain several physical servers was expensive for organizations.
As a solution, virtualization was introduced. It allows running of multiple Virtual Machines (VMs) on a single physical server’s CPU. Isolation of applications between VMs and a level of security is provided by virtualization as the information of one application cannot be freely accessed by another application.
Better utilization of resources in a physical server and better scalability is possible because an application can be added or updated easily as well as reducing hardware costs. Each VM is a full machine running all the components, including its own operating system, on top of the virtualized hardware.
Containers are like VMs, but they have relaxed isolation properties to share the Operating System (OS) among the applications. So containers are considered lightweight. Like a VM, a container has its own filesystem, CPU, memory, process space, and more. They are portable across clouds and OS distributions as they are decoupled from the underlying infrastructure.
Containers can be very useful to bundle and run applications. In a production environment managing the containers that run the applications and ensuring that there is no downtime is necessary. If this behavior is handled by a system, then it will be much easier and that’s how Kubernetes came into the picture. Kubernetes provides with a framework to run distributed systems resiliently. It takes care of scaling requirements, failover, deployment patterns, and more.
The diagram below will help in better visualizing the above points :
Let us first learn some words specific to Kubernetes
Kubernetes targets management of elastic applications consisting of multiple microservices communicating with each other. Often those microservices are tightly coupled forming a group of containers that would typically, in a non-containerized setup run together on one server. This group, the smallest unit that can be scheduled to be deployed through K8s is called a pod.
This group of containers would share storage, Linux namespaces, cgroups, IP addresses. These are co-located, resulting in sharing of resources and these are always scheduled together.
Pods have a short life span. They are created, destroyed and re-created on demand, based on the server state and service.
As pods have a short lifetime, there is no guarantee about the IP address they are served on. This could make the communication of microservices hard. Hence K8s has introduced the concept of a service, which is an abstraction on top of several pods, typically requiring to run a proxy on top, for other services to communicate with it via a Virtual IP address. This is where configuration of load balancing of numerous pods and exposing them via a service has resulted.
Several parts make up the K8 setup, some of which are optional and some mandatory for the whole system to function.
This is a high-level diagram of the architecture:
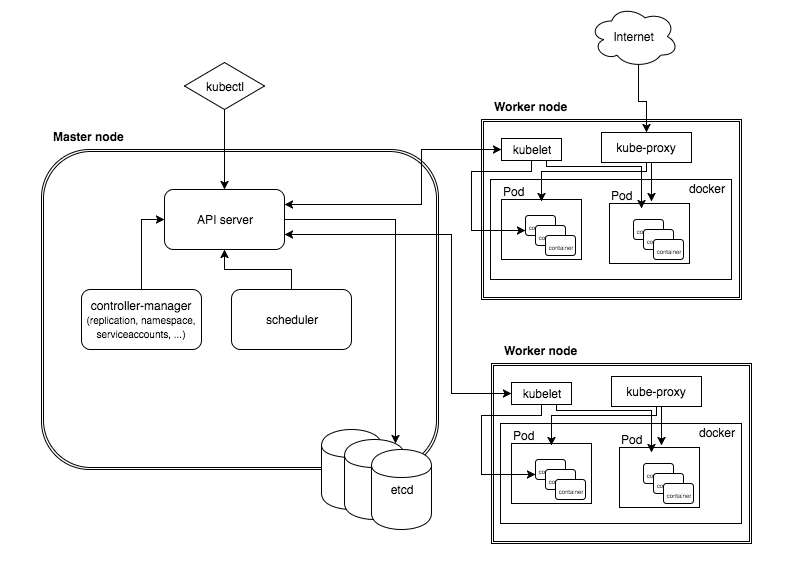
Let’s have a look into each of the component’s responsibilities:
Kubernetes cluster is managed by the master node. This is the entry point of all administrative tasks. Taking care of orchestrating the worker nodes, where the actual services are running is the responsibility of master node.
Let's discuss each of these components of the master node in detail now:
Entry points for all the REST commands used to control the cluster is the API server. In addition to REST requests being processed and validated, executing the bound business logic are carried out by this server. The result state must be persisted somewhere, and that brings us to the next component of the master node.
etcd is a simple, distributed, consistent key-value store. Its primary use is for shared configuration and service discovery. A REST API for CRUD operations is provided as well as an interface to register watchers on specific nodes enabling a reliable way to notify the rest of the cluster about configuration changes.
The deployment of configured pods and services onto the nodes happens because of the scheduler component. It has the information regarding resources available on the members of the cluster, as well as the ones required for the configured service to run and hence the decision to deploy a specific service can be made.
Different kinds of controllers inside the master node can be run optionally. Controller-manager is a daemon embedding those. A controller uses api server to watch the shared state of the cluster. It makes corrective changes to the current state and change it to the desired one.
Some examples of controllers are Replication controller, endpoints controller, namespace controller, and service accounts controller.
The pods are run here, so the worker node contains all the necessary services to manage the networking between the containers, communicate with the master node, and assign resources to the containers scheduled.
Docker runs the configured pods and runs on each of the worker nodes. Downloading of images and starting the containers is taken care by docker.
kubelet gets the configuration of a pod from the api server and ensures that the described containers are up and running. Communicating with the master node happens via this worker service. Communicating with etcd, to get information about services and write the details about newly created ones happens through kubelet.
It acts as a network proxy and a load balancer for a service on a single worker node. It takes care of the network routing for TCP and UDP packets.
A command line tool to communicate with the API service and send commands to the master node.
Around 9,967 companies currently use Kubernetes. Most of these companies are US based and in the Computer Software industry. Kubernetes is most often used by companies with 10-50 employees and 1M-10M dollars in revenue. Some examples are:
Scale and complexity of projects is ever changing in today’s world making project and operations management a very hectic task. Kubernetes automatically scales and manages containers which are used to deploy and test project or application modules which counters this problem. Moreover it is very easy to learn, use, and integrate with existing projects.
Most importantly unlike most open source projects, Kubernetes had the benefit of being refined for years in production at one of the world's largest tech companies. Borg, the predecessor of Kubernetes which was Google's own internal "container-oriented cluster-management system" made the architects of Kubernetes wiser and they made sure to include things which were missing or not up to the mark in Borg.
A course in Kubernetes is quite in demand in present times. It can easily be inferred after looking at the various job postings that several job postings for DevOps professionals now require understanding of container orchestration using Kubernetes. There are multiple openings for DevOps experts with Kubernetes experience in big companies like Microsoft, IBM, Infosys.
Moreover, there are also hundreds of startups that have based their businesses solely on Kubernetes. So, learning Kubernetes in addition to being beneficial for experienced professionals, will also help entry to mid-level professionals who can bag lucrative jobs.
A DevOps Engineer with hands-on Kubernetes experience can expect a salary package which is more than the median value in the Indian industry. Overseas, the salary packages are even higher. Average salary of a Software Engineer with Kubernetes skills is around $114,287* per annum in the United States. A Software Engineer, proficient in Kubernetes can draw an annual salary of Rs 1,047,619* (*as per PayScale) Kubernetes is one of the upcoming technologies. Adding this to one’s technology portfolio will benefit in boosting career prospects along with adding a few extra zeros to the annual packages.
To summarize Kubernetes is a powerful deployment tool for DevOps teams to keep up their pace with day to day workflows of modern software development. In absence of such tools the SDE’s will have to themselves write their own deployment scripts, scaling and updates around workflows. With maximum utilization of containers, ease of building cloud native applications that can be deployed from anywhere and its non-dependency of cloud specific requirement comes as cherry on the top. Thus, if one is looking to use efficient model for application development and operation, Kubernetes is your one stop solution.
Optimistik Infosystems Pvt. Ltd. is an established name for delivering quality training and consulting solutions to Information Technology (IT) and ITeS eco-system. We serve prestigious ISVs & SIs and also to the learning needs of Individuals, groups & institutions. In a short span, we have created our reputation as reliable training and consulting partners by providing quality trainings and best solutions. Our key competency lies in catering high end and challenging learning solutions to the software development community.